Distributed Computing @ OMSCS over – what a ride!
Last semester, I decided to enroll in the brand spanking new Georgia Tech’s Distributed Computing course offered for the first time (as part of OMSCS) thi...
Last semester, I decided to enroll in the brand spanking new Georgia Tech’s Distributed Computing course offered for the first time (as part of OMSCS) thi...

Distributed Computing was offered in the OMSCS program for the first time this past semester (i.e. Spring 2021) and when the course opened up for registration, ...

I just finished Spring 2021 at Georgia Tech OMSCS and published a farewell note on the classroom’s forum (i.e. Piazza platform) and would like to share th...

The above diagram I diagrammed illustrates the impact to a network packet when setting the maximum segment size in iperf3. With an MSS of 1436, the segment (i.e...
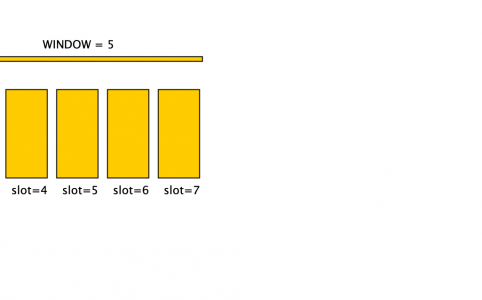
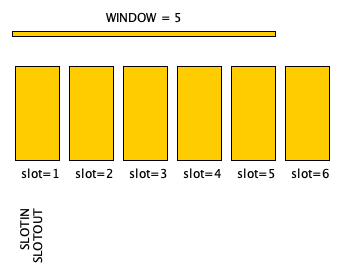
In the paper “PAXOS made moderately complex”, the authors introduce unfamiliar concepts not mentioned in the original PAXOS paper, concepts such as ...
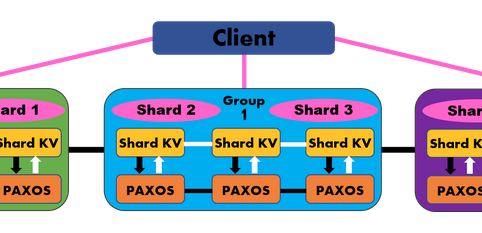
I’m now half way through Distributed Computing course at Georgia Tech and us students are now tackling the penultimate project: building a replicated stat...
I’m preparing for my Distributing Systems midterm and I was struggling to understand the differences between serializability and linearizability (why are ...
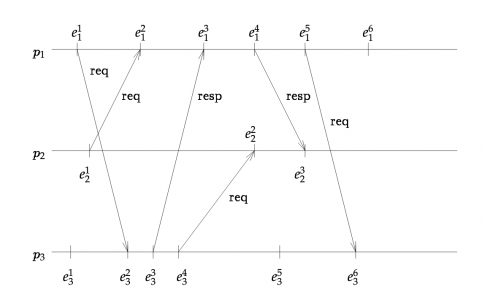
In “Consistent Global States of Distributed Systems: Fundamental Concepts and Mechanisms”, the authors propose capturing a distributed system’...

Leslie Lamport, a world renounced computer scientist, first published the paper “Part-time parliament” back in 1990. Unfortunately, that paper well ...

For this week, my distributed systems course just assigned us students a reading assignment: “Impossibility of distributed consensus with one faulty proce...