Question 3d
The algorithm is implemented on a cache coherent architecture with an invalidation-based shared-memory bus.
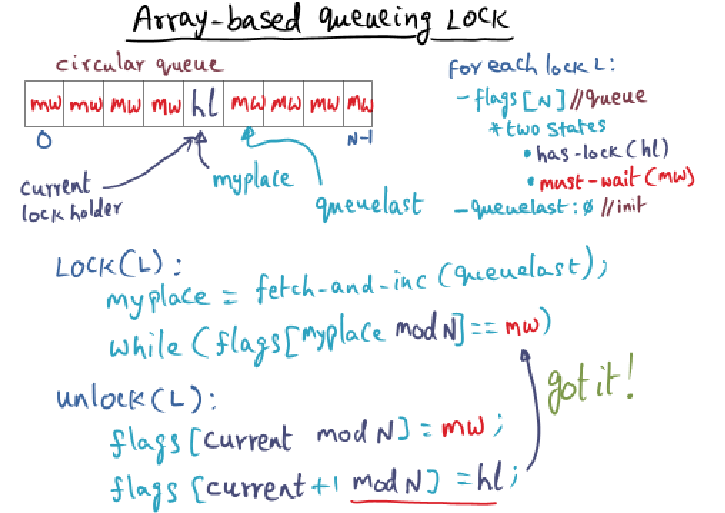
The circular queue is implemented as an array of consecutive bytes in memory such that each waiting thread has a distinct memory location to spin on. Let’s assume there are N threads (each running on distinct processors) waiting behind the current lock holder.
If I have N threads, and each one waits its turn to grab the lock once (for a total of N lock operations), I may see far more than N messages on the shared memory bus. Why is that?
My Guess
- Wow .. I’m not entirely sure why you would see far more than N messages because I had thought each thread spins on its own private variable. And when the current lock holder bumps the subsequent array’s flag to has lock … wait. Okay, mid typing I think I get it. Even though each thread spins on its own variable, the bus will update all the other processor’s private cache, regardless of whether they are spinning on that variable.
Solution
- This is due to false-sharing.
- The cache-line is the unit of coherence maintenance and may contain
multiple contiguous bytes. - Each thread spin-waits for its flag (which is cached) to be set to hl.
- In a cache-coherent architecture, any write performed on a shared
memory location invalidates the cache-line that contains the location
in peer caches. - All the threads that have their distinct spin locations in that same
cache line will receive cache invalidations. - This cascades into those threads having to refresh their caches by
contending on the shared memory bus.
Reflection
Right: the array belongs in the same cache line and the cache line may contain multiple contiguous bytes. We just talked about all of this during the last war room session.
Question 3e
Give the rationale for choosing to use a spinlock algorithm as opposed to blocking (i.e., de-scheduling) a thread that fails to get a lock.
My Guess
- Reduced complexity for a spin lock algorithm
- May be simpler to deal with when there’s no cache coherence offered by the hardware itself
Solution
Critical sections (governed by a lock) are small for well-structured parallel programs. Thus, cost of spinning on the lock is expected to be far lesser than the cost of context switching if the thread is de- scheduled.
Reflection
Key take away here is a reduced critical section and cheaper than a context switch
Question 3f
(Answer True/False with justification)(No credit without justification)
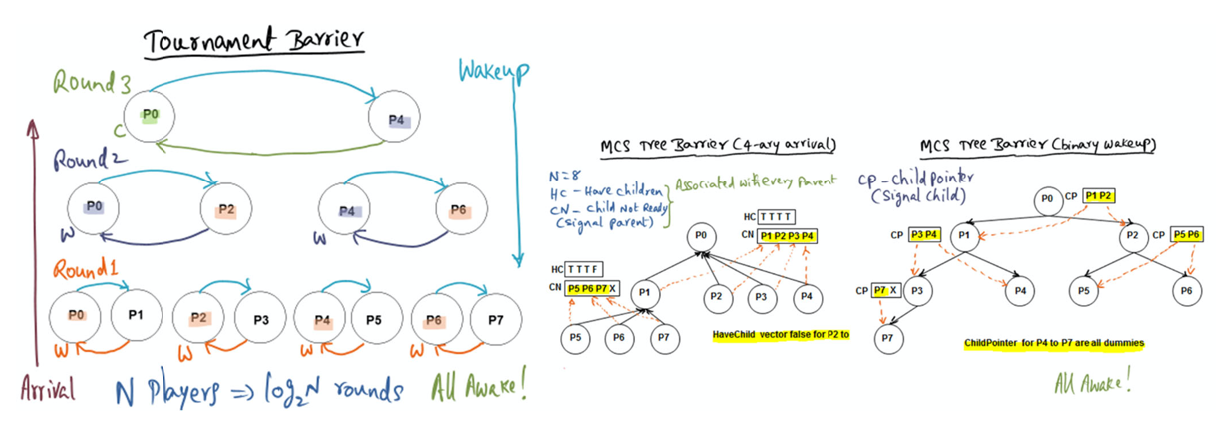
In a large-scale CC-NUMA machine, which has a rich inter-connection network (as opposed to a single shared bus as in an SMP), MCS barrier is expected to perform better than tournament barrier.
Guess
- The answer is not obvious to me. What does having a CC (cache coherence) numa machine — with a rich interconnection network instead of a single shared bus — offer that would make us choose an MCS barrier over a tournament barrier …
- The fact that there’s not a single shared bus makes me think that this becomes less of a bottle neck for cache invalidation (or cache update).
Solution
False. Tournament barrier can exploit the multiple paths available in the interconnect for parallel communication among the pair-wise contestants in each round. On the other hand, MCS due to its structure requires the children to communicate to the designated parent which may end up sequentializing the communication and not exploiting the available hardware parallelism in the interconnect.
Reflection
Sounds line the strict 1:N relationship between the parent and the children may cause a bottle neck (i.e. sequential communication).
3g Question
In a centralized counting barrier, the global variable “sense” informs a processor which barrier (0 or 1) it is currently in. For the tournament and dissemination barriers, how does a processor know which barrier (0 or 1) it is in?
Guess
- I thought that regardless of which barrier (including tournament and dissemination), they all require sense reversal. But maybe …. not?
- Maybe they don’t require a sense since the threads cannot proceed until they reach convergence. In the case of tournament, they are in the same barrier until the “winner” percolates and the signal to wake up trickles down. Same concept applies for dissemination.
Solution
Both these algorithms do not rely on globally shared data structures. Each processor knows “locally” when it is done with a barrier and is in the next phase of the computation. Thus, each processor can locally flip its sense flag, and use this local information in its communication with the other processors.
Reflection
Key take away here is that neither tournament nor sense barrier share global data structures. Therefore, each processor can flip its own sense flag.
3h
Tornado uses the concept of a “clustered” object which has the nice property that the object reference is the same regardless of where the reference originates. But a given object reference may get de-referenced to a specific representation of that object. Answer the following questions with respect to the concept of a clustered object.
The choice of representation for the clustered object is dictated by the application running on top of Tornado.
Guess
No. The choice of representation is determined by the operating system. So unless the OS itself is considered an application, I would disagree.
Solution
The applications see only the standard Unix interface. Clustered object is an implementation vehicle for Tornado for efficient implementation of system
services to increase concurrency and avoid serial bottlenecks. Thus choice of representation for a given clustered object is an implementation/optimization choice internal to Tornado for which the application program has no visibility.
Reflection
Key point here is that the applications see a standard Uni interface. And that the clustered object is an implementation detail for Tornado to 1) increase concurrency and 2) avoid serial bottlenecks (that’s why there are regions and file memory caches and so on).
Question 3h
Corey has the concept of “shares” that an application thread can use to give a “hint” to the kernel its intent to share or not share some resource it has been allocated by the kernel. How is this “hint” used by the kernel
Guess
The hint is used by the kernel to co-locate threads on the same process or in the case of “not sharing” ensure that there’s no shared memory data structure.
Answer
In a multicore processor, threads of the same application could be executing on different cores of the processor. If a resource allocated by the kernel to a particular thread (e.g., a file descriptor or a network handle) is NOT SHARED by that thread with other threads, it gives an opportunity for the kernel to optimize the representation of the associated kernel data structure in such a way as to avoid hardware coherence maintenance traffic among the cores.
Reflection
Similar theme to all the other questions: need to be very specific. Mainly, “allow kernel to optimize representation of data structure to avoid hardware coherence maintenance traffic among the cores.
Question 3j
Imagine you have a shared-memory NUMA architecture with 8 cores whose caches are structured in a ring (as shown below). Each core’s cache can only communicate directly with the one next to it (communication with far cores has to propagate among all the caches between the cores). Overhead to contact a far memory is high (proportional to the distance in number of hops from the far memory) relative to computation that accesses only its local NUMA piece of the memory.
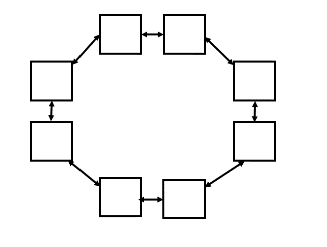
Would you expect the Tournament or Dissemination barrier to have the shortest worst-case latency in this scenario? Justify your answer. (assume nodes are laid out optimally to minimize communication commensurate with the two algorithms). Here we define latency as the time between when the last node enters the barrier, and the last node leaves the barrier.
Guess
- In a dissemenation barrier, the algorithm is to hear back from (i+2^k) mod n. As a result, each process needs to talk to another distant processor.
- Now what about Tournament barrier, where the rounds are pre determined?
- I think with tournament barrier, we can fix the rounds such that the processors speak to its closest node?
Solution
Dissemination barrier would have the shortest worst-case latency in this scenario.
In the Tournament barrier, there are three rounds and since the caches can communicate with only the adjacent nodes directly, the latency differs in each round as follows:
- First round: Tournament happens between adjacent nodes and as that can happen parallelly, the latency is 1.
- Second round: Tournament happens between 2 pairs of nodes won from previous round which are at a distance 2 from their oppoent node. So, the latency is 2 (parallel execution between the 2 pairs).
- Third round: Tournament happens between last pair of nodes which are at distance 4 from each other, making the latency 4.
The latency is therefore 7 for arrival. Similar communication happens while the nodes are woken up and the latency is 7 again. Hence, the latency caused by the tournament barrier after the last node arrives at the barrier is 7+7 = 14.
In the dissemination barrier, there are 3 rounds as well.
- First round: Every node communicates with its adjacent node
(parallelly) and the latency is 1. (Here, the last node communicates
with the first node which are also connected directly). - Second round: Every node communicates with the node at a distance 2
from itself and the latency is 2. - Third round: Every node communicates with the node at a distance 4
from itself and the latency is 4. The latency is therefore 7.
Hence, we can see that dissemination barrier has shorter latency than the tournament barrier. Though the dissemination barrier involves a greater number of communication than the tournament barrier, since all the communication at each round can be done in parallel, the latency is lesser for it.
Reflection
Right, I forgot completely that with a tournament barrier, there needs to be back propagation to signal the wake up as well, unlike the dissementation barrier, which converges hearing from ceil(log2n) neighbors due to its parallel nature.