The key take away for scheduling is that as OS designers you want to follow this mantra: “keep the caches warm“. Following this principle will ensure that the scheduler performs well.
There are many different scheduling algorithms including first come first serve (FCFS), fixed processor (focus on fairness), fixed processor (thread runs on the same process every time), last processor scheduling (processor will select thread that last ran on it, defaulting to choosing any thread), and minimum intervening (checks what other threads ran between, focusing on cache affinity). One modification to minimum intervening is a minimum intervening with a queue (since threads sitting in the queue may pollute the cache as well, so we’ll want to choose the minimum between the two).
One major point of the different scheduling algorithms is that there’s no correct answer: we need to look at trends and look at the overhead. The latter option (i.e. minimum intervening thread with queues) seems like the best solution but really what about the hidden costs like keeping track of the internal data structures?
Regardless of which of the above policies are chosen, the OS designer must exercise caution during implementation. Although designing the policy with a single global queue may work for a small system with a handful of processors or threads, imagine a system with dozens of processors and hundreds of threads: what then? Perhaps build affinity-based local queues instead, each queue policy specific (nice for flexibility too).
Finally, for performance, think about how to avoid polluting the cache. Ensure that the memory footprint of the threads (either frugal or hungry threads, combination of the two) footprint do not exceed the L2 cache. Determining what threads are frugal or hungry requires the operating system to profile the processes, additional overhead to the OS. So we’ll want to minimize profiling.
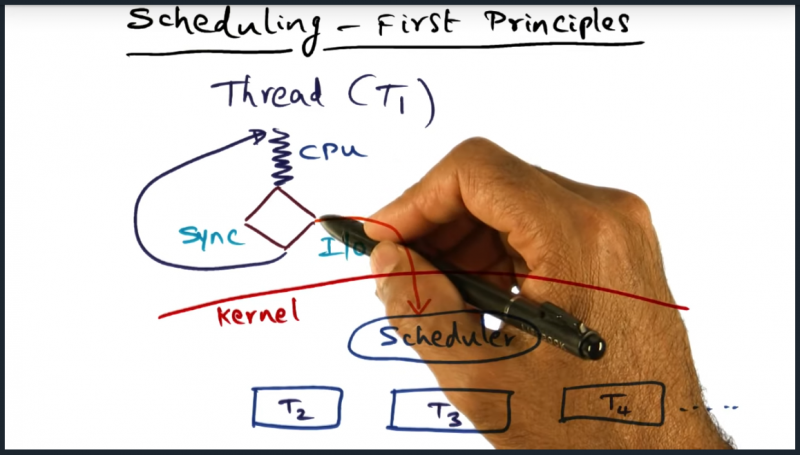
Scheduling First Principles
Summary
Mantra is always the same: “keep the caches warm”. That being said, how do we (as OS designers), when designing our schedulers, choose which thread or process that should run next?
Quiz: Scheduler
Summary
How should scheduler choose the next thread – all of the answers are suitable. Remainder of lecture will focus on “thread whose memory contents are in the cpu cache”. So … what sort of algorithm will we come up with determine whether another processor’s have its contents in the cache. I can imagine a few naive solutions
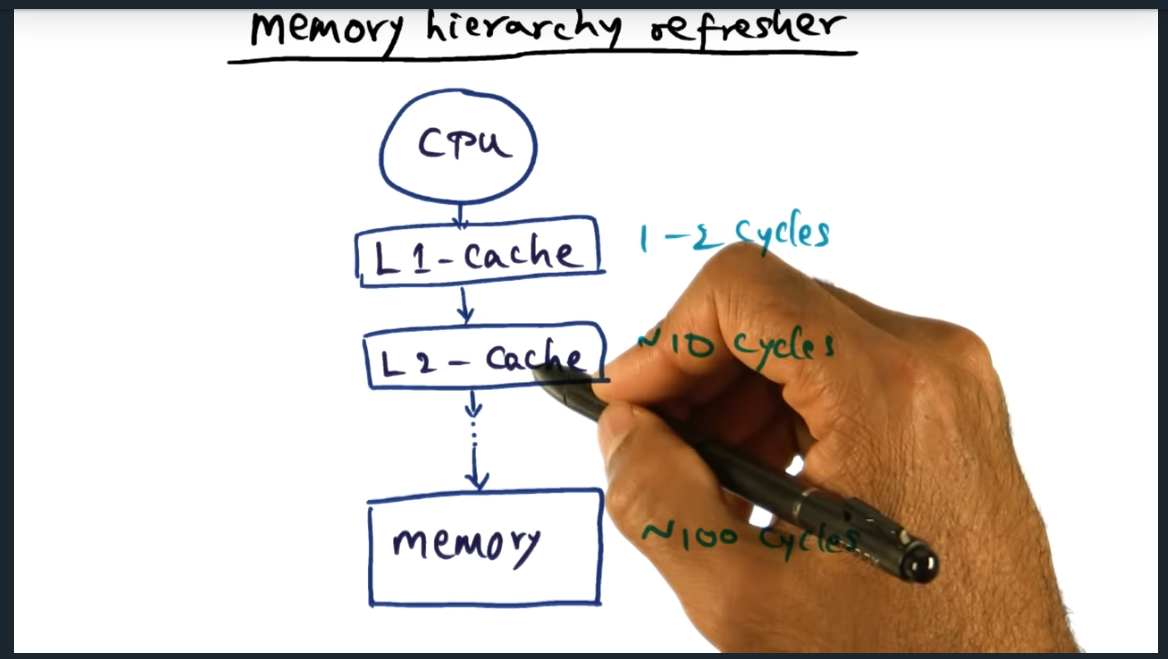
Memory Hierarchy Refresher
Summary
Going from cache to memory is a heavy price to pay, more than two orders of magnitude. L1 cache takes 1-2 cycles, L2 around 10 cycles, and memory around 100 cycles
Cache affinity scheduling
Summary
Ideally a thread gets rescheduled on the same processor as it ran on before. However, this might not be possible due to intervening threads, the cache being polluted.
Scheduling Policies
Summary
Different types of scheduling policies including first come first serve (focuses on fairness, not affinity), fixed processor scheduling (every thread runs on the same processor every time), last processor scheduling (processor will pick thread that it previously ran, falling through to picking any thread), and minimum intervening (most sophisticated but requires state tracking).
Minimum Intervening Policy
Summary
For a given thread (say Ti), the affinity is the number of threads that ran in between Ti’s execution
Minimum Intervening Plus Queue Policy
Summary
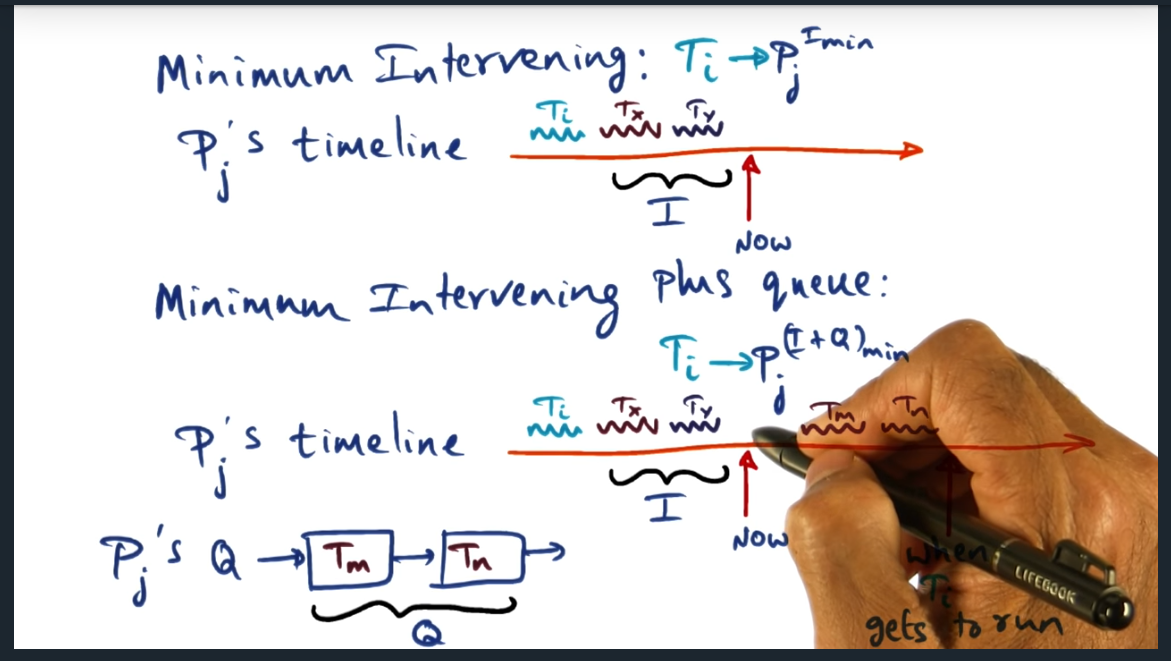
Attributes of OS is to quickly make a decision and get out of the way, hence why we might want to employ minimum intervening scheduler (with limits). Separately, we want our scheduler to take into account of the queued threads, not just the affinity, since it’s entirely possible for affinity to be low for a CPU but for the queue to contain other threads, polluting the cache. So the minimum intervening plus queue takes both the affinity and the queued threads into account
Summarizing Scheduling Policies
Summary
Scheduling policies can be categorized into processor centric (what thread should a particular processor should choose to maximize chance of cache amount of cache content will be relevant) and thread centric (what is the best decision for a particular thread with respects to its execution). Thread centric: fixed and last processor scheduling policies. Processor centric is minimum intervening and intervening plus queue.
Quiz: Scheduling Policy
Summary
With the Minimum interleaving with queues, we select the processor that has the minimum value between number of intervening threads and minimum number of items in the queue.
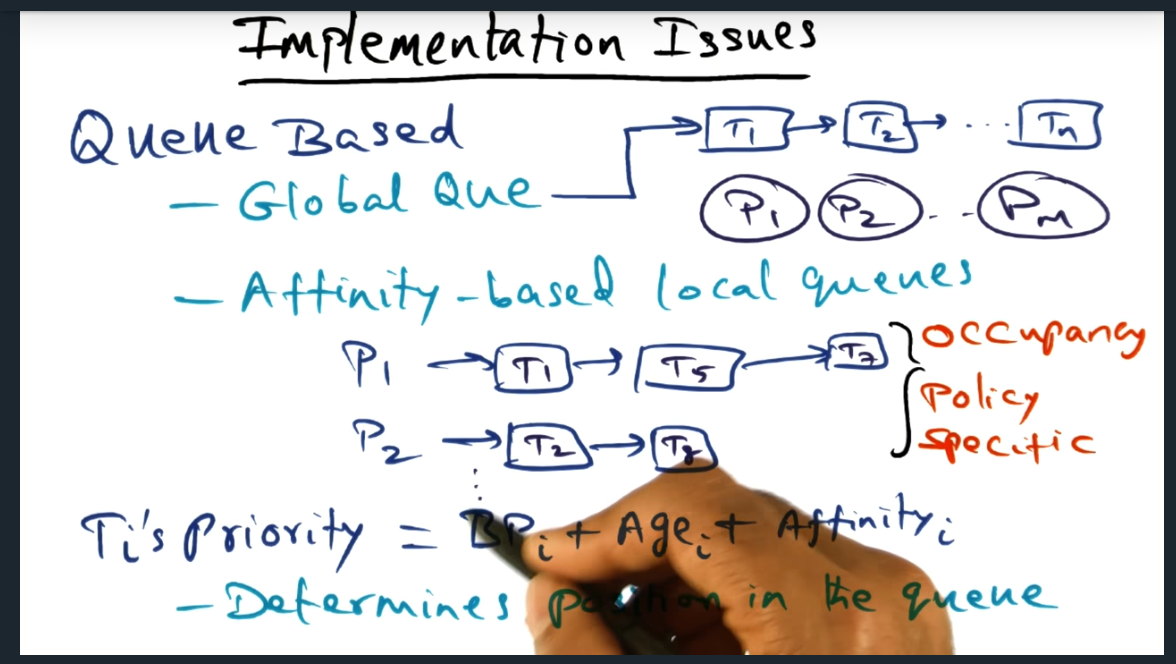
Implementation Issues
Summary
One way to implement the scheduling is to use a global queue. But this may be problematic for systems with lots of processors. Another approach is to have one queue per processor, and each queue can have its own policy (e.g. first come first served, fixed processor, minimum intervening). And within the queue itself, the threads position’s is determined by: base priority (when thread first launched), age (how long thread has been around) and affinity
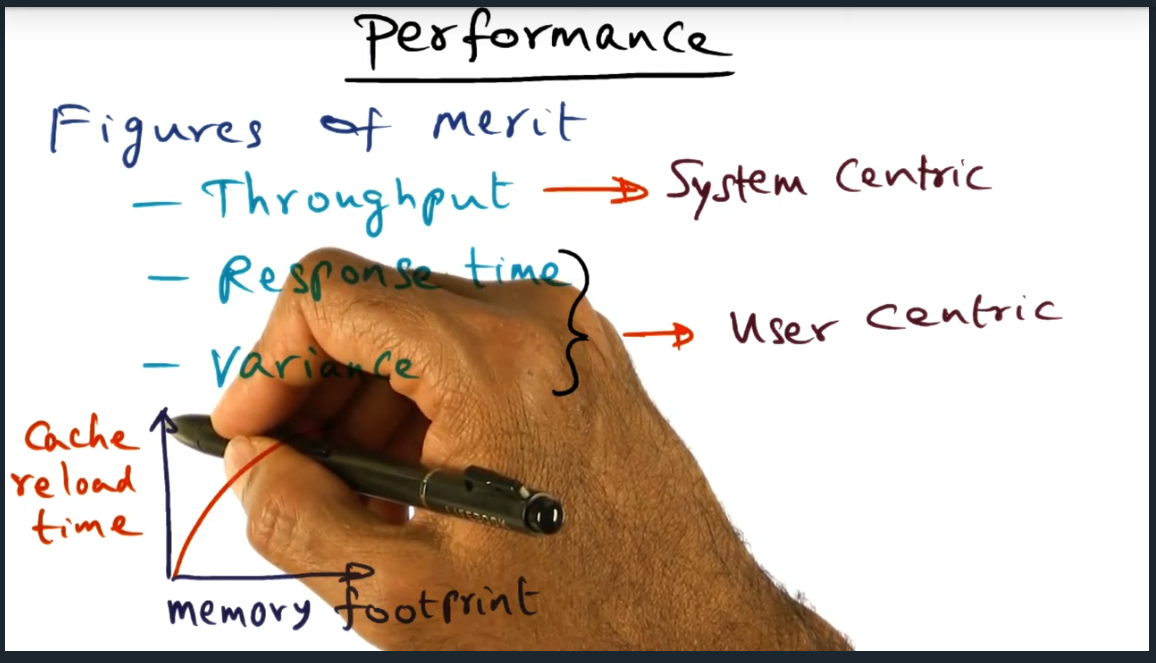
Performance
Summary
How do we evaluate the scheduling policies? We can look at it from the system’s point of view: throughput. That is, what are the number of threads that get executed per unit of time. From another viewpoint: user centric, which consists of response time (end to end time) and variance (i.e. deviation of end to end times). With that in mind, the first come first serve would perform poorly due to high variance, given that policy does not distinguish one thread from another thread
Performance continued
Summary
A minimum intervening policy may not suitable for all work loads. Although the policy may work well for small to light to medium work loads, may not perform very well when system under stress because caches will get polluted. In this case, a fixed processing scheduling may be more performant. So no one size fits all. Also, may want to introduce delays in scheduling, a technique that works in both synchronization and in file systems (which I will learn later on in the course, apparently)
Cache Affinity and Multicore
Summary
Hardware can switch out threads seamlessly without the operating system’s knowledge. But there’s a partnership between hardware and the OS. The OS tries to ensure that the working set lives in either L1 or at L2 cache; missing in these caches and going to main memory is expensive: again, can be twice order of magnitude.
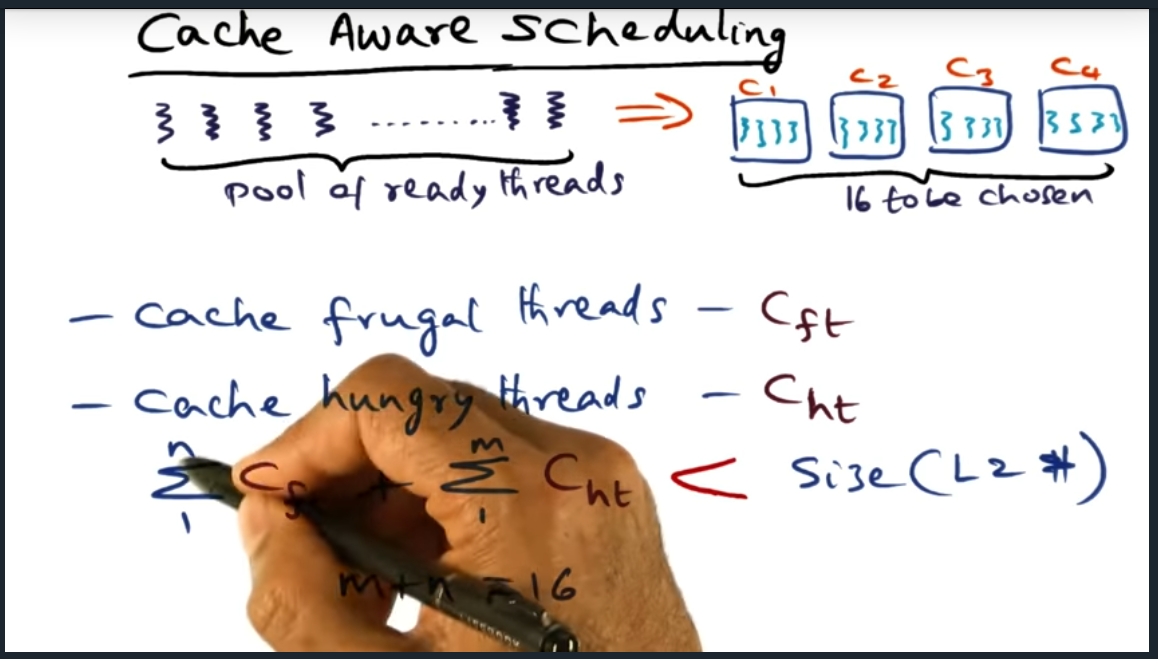
Cache Aware Scheduling
Summary
For cache aware scheduling, we categorize threads into two: cache hungry and cache frugal. Say we have 16 hardware threads, we want to make sure that during profiling, we group them and make sure that cache size of hungry and cache size of frugal have a working set size less than cache (L2). But OS must be careful to profiling and monitoring — should not heavily interfere. In short, overhead needs to be minimal.