As a software programmer, I always had a vague understanding of how an operating system fetches data from memory. At an abstract level, I understood that a processor requests data from the memory controller, sending a message (with the memory address encoded) across the bus.
But I learned recently that in addition to the system’s physical memory—the same memory I used to squeeze into the motherboard when installing RAM—there are multiple hardware caches, completely abstracted from the programmer.
These caches sit between the processor and main memory, called: L1 cache and L2 cache and L3 cache. Each cache differs: in cost, in size, and in distance from the CPU. The lower the digit, the higher cost, the smaller in size, and the closer it sits to CPU. For example, if we compare L1 and L2 cache, L1 costs more, holds less data, and sits closer to the processor.
When the processor wants to retrieve data from memory, it sends a request first lands in L1 cache’s world. If L1 has that memory page cached, it immediately sends that data back to the processor, preventing the request from unnecessarily flowing towards the memory controller. This pattern of checking local cache and forwarding requests repeats until the request eventually reaches the memory controller, where data is actually stored.
The further we allow the CPU’s request to travel down the bus, we penalize the CPU, forcing it to wait, like a car at a stop sign, for longer cycles. For example, the CPU waits 4 cycles for L1 cache, 12 cycles for L2, 36 cycles for L3, and—wait for it—62 cycles when accessing main memory. Therefore, we strive to design systems that cache as much data as possible and as close to the CPU, increasing overall system performance.
We break down a cache into the following components:
- Blocks
- Lines
- Sets
- Tag
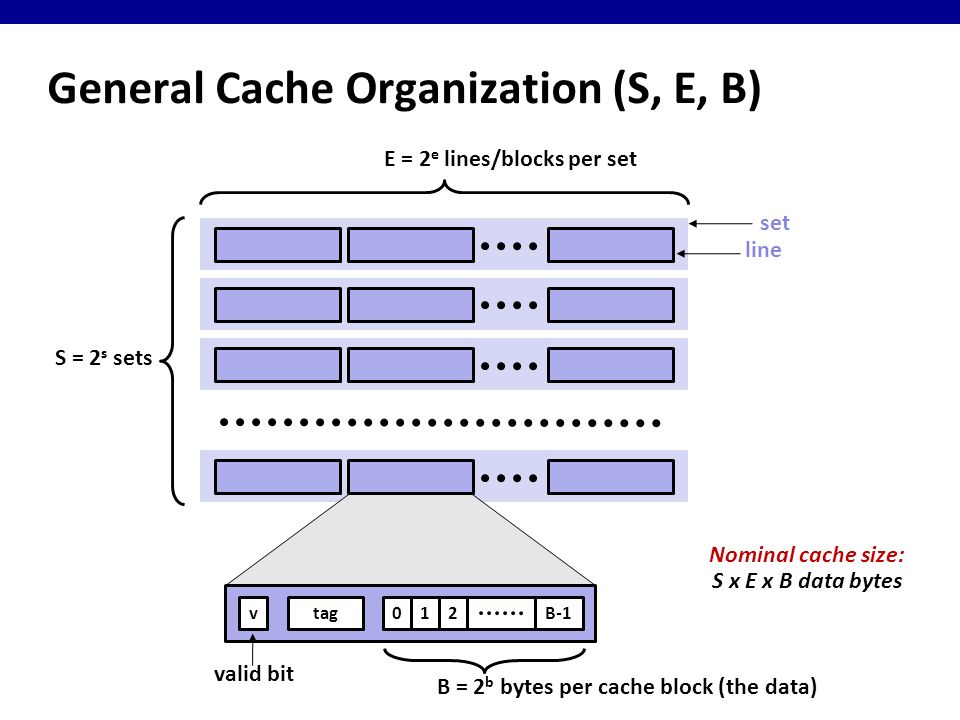
As you can see from the image above, we organize our cache sets (S), lines (L), and blocks (B). One block of data represents 8 bits (1 byte) and every block of data is represented by a physical memory address. For example, the memory address 0x0000 may store 010101010 and 0x0001 may store 01110111 another. We group these blocks together into a line, which store sequential blocks. A line may store two or four or eight or sixteen bytes—it all depends on how we design the system. Finally, each line belongs to a set, a bucket that stores one or more lines. Like the number of bytes a line stores, a set can store one or two or three or forty—again, it all depends on our design.
Together, the total number of sets, number of lines, and number of bytes determine the cache’s size, calculated with the following formula: cache size = S x E x B.
In the next post, I’ll cover how a cache processes a memory address, determining whether it retrieves memory from cache or forwards the request to the next cache (or memory controller).